I think about evolved antennas a lot.
If you’re not familiar, an evolved antenna is created when you set an evolutionary algorithm on the task of producing a structure that is as efficient at its intended function as possible. Past that there’s no human input, the algorithm just does its thing. It:
- Modifies elements of the initial design,
- Evaluates how well the design would perform according to a set of requirements,
- Adds or discards the changes accordingly, then
- Repeats until a success threshold has been achieved via iteration.
Some evolved antenna practices also create a series of designs in parallel. They then pit the outputs against each other as a final layer of proving out efficacy.
This process mimics natural selection. Here, mutations that are beneficial to surviving in an environment are passed through generations. It also creates absolutely wild, alien outputs:

An evolved antenna looks the way it does because the algorithm that creates it is focused on the efficiency of the artifact it produces. It has no concept of what antennas are “supposed to look like”. That’s a bias that is inherent to us humans.
Structural limitations
I also have a light fascination with early programming. Specifically, the creativity involved with how programmers accommodated limitations inherent with the medium.
Early mainframe programmers were constrained to the point where there would be a limit on the number of characters you could use, which led to cryptic names that oftentimes required a physical dictionary to look up the human-friendly meaning of something.
There was also a long tail of this practice even after the hardware-imposed restrictions of the mainframe era. This was likely built on muscle memory, “best practice”, and a DRY mindset taken too far. Fortunately, contemporary practice—where computational power is far more luxurious—favors clarity over brevity.
Profusion and proliferation
Nowadays function and variable names are long and luxurious. We’re inundated with text. Flooded by it, even.
In fact, we’ve gotten so good at using text that we built software to produce it for us, on demand and at volume.
There have been some good things to come out of this development if you make digital experiences for a living. Concerns such as documentation, design systems, styleguides, and other vital-yet-neglected areas of the practice are suddenly critical for operations.
It turns out that written words that help to explain things and create consistency are extremely important. Who knew!
Here, I must confess: As someone who has long-favored these downplayed and underfunded areas of the trade, I have found myself ugly laughing at this tragicomic phenomenon. I also know that being able to feel this smug ruefulness is on borrowed time.
Returning to this sudden explosion of text content—as well as other factors—we now have words for everyone who wants, or may eventually need them.
Well, anyone who can pay.
Decoupling and system gaming
Many contemporary LLM-providing companies operate under a model where you pay them proportionate to how much computational power you utilize. This is sold via tokens, which is an abstract representation of a segment of content to be processed.
Money is something people are reluctant to part ways with. This creates incentives to get creative. I’ve read all sorts of clever techniques, tricks, optimizations, and hacks people have created to lower token expenditure.
The one that stands out to me most is the caveman prompt. It promises to “[cut] 65% of tokens by talking like caveman”. Of note is its ability to specify the level of “grunt”:
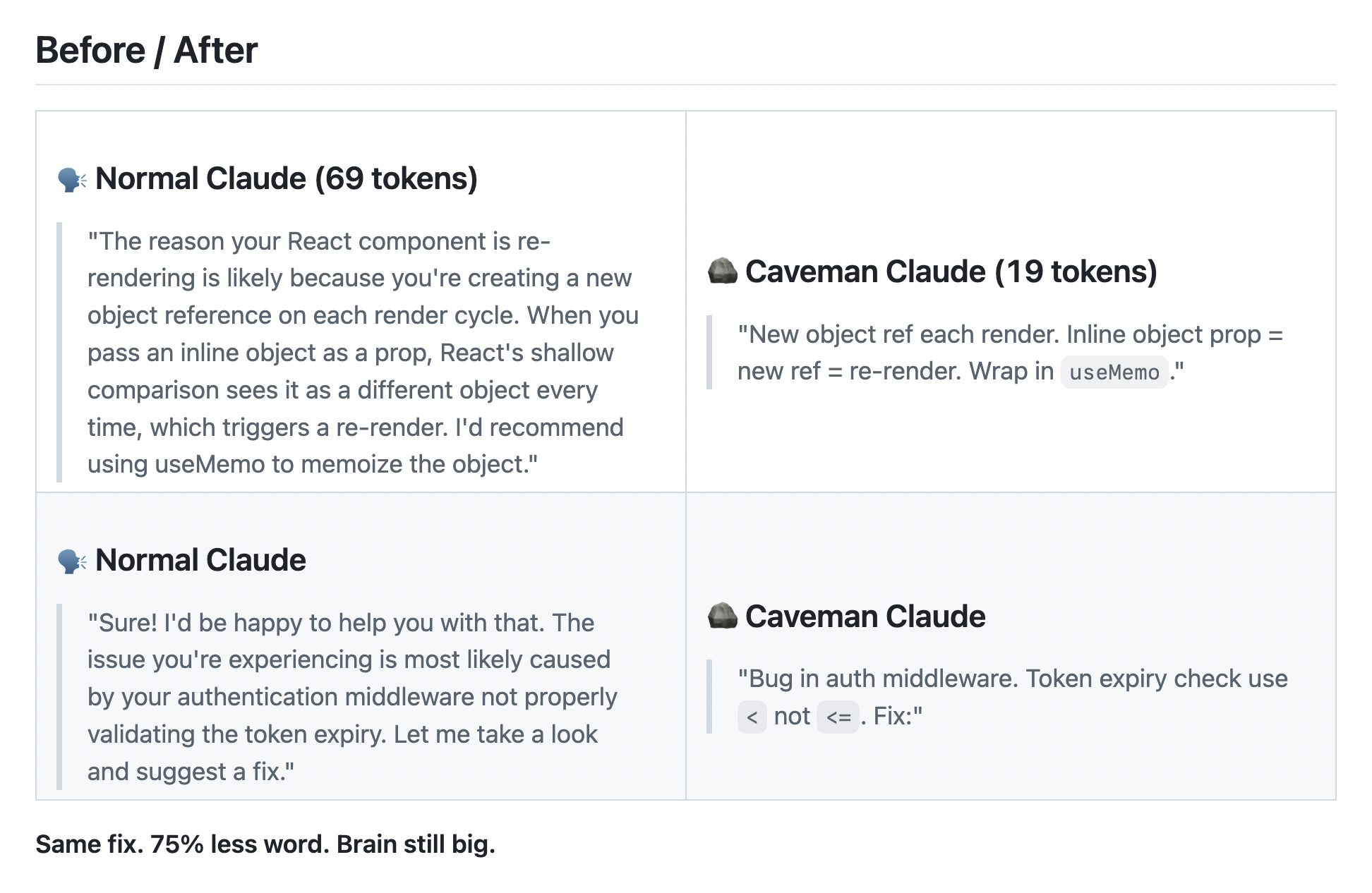
Futurecasting
The caveman prompt is a signal.
Right now we live in a space where full, complete words and sentences are still desirable for us humans, and LLMs work with it. This space is in competition with a few intractable realities:
- LLM companies are continuing to operate at a loss. The real cost of using their services may manifest sooner than later, as promises of profitability need to be kept.
- Human language is an inefficient medium for transmitting data, and largely lacks the precision needed to describe the logic that powers contemporary software. Consider concepts like Robot Interaction Language and ggwave as ways we’ve attempted to address this fact.
- LLM-based product development is focused more on what is produced compared to how it is made.
Given these considerations, one can imagine a future where human-friendly language is a liability. The forces of cost and efficiency are difficult to overcome, especially if results can be generated with minimal effort.
One can also imagine that code returns to its infant state of being terse, cryptic, and near-impenetrable due to efforts to optimize how LLMs operate. Here, human language sets the parameters and LLMs act as the dictionary.
This LLM optimization might even go a step further. In the pursuit of efficiency its code output becomes a language completely decoupled from a human’s ability to follow.
In the torrential downpour that is everyone saying the quiet part out loud, the CEO of OpenAI’s horrifying comment about selling our intelligence back to us is a raindrop worth paying attention to.
This possible outcome may mean that this time around there is no dictionary to reference. Or there is a dictionary, but it is sold back to you at a premium. It’s easy to foresee a proprietary language that only a LLM vendor can compile, decode, and otherwise change—it’s not like there’s a lack of prior art.
Preventative measures
Science fiction author Vernor Vinge wrote a brilliant book titled Rainbow’s End. In it, a character named Robert Gu is cured of his Alzheimer’s and brought into a post-singularity world. Gu—a former English professor and avowed technophile—struggles to adapt to a radically changed world.
In one notable scene from the book, Gu rages when dismantling a device. He finds all its internal components are sealed and labeled, informing him that there are “no user-serviceable parts within”.
Code may be poised to follow this direction. Imagine a world where attempting to open up any piece of software reveals a dense forest of evolved antennas, each constructed using inscrutable, black box language.
Gu's outburst of anger is valid. It stems from understanding that intentionally preventing someone from making modifications is a method of enacting control.
Another notable part of the future Rainbow’s End posits is the mass-proliferation of augmented reality. Here, people can access different “layers” of perception, with paid tiers of information. Looking with your naked eyes is free, but the more information you want about something the more you need to spend.
Craft and cost
As someone who cares about craft, I am deeply worried about this potential future. How something is built is just as important as the results it produces—reference LLMs' bias towards producing inaccessible code as an immediate concern.
Inaccessible output by default is a case of implicit and unwitting control, in that it shapes who can—and cannot—use the web. The companies that provide these models could hypothetically be compelled to address that.
However, the much-needed regulation needed to prevent this systemic digital exclusion is unlikely to happen with the current status quo. Or more realistically, will happen in a way that is more in-line with the regressive path the United States is currently traveling down.
Some here may argue that these systems are performing better than how human developers have, and that will increase as LLM-generated code becomes more prevalent. Here, know that:
- As of now, homepage accessibility errors and complexity are both on the rise, and
- This increase in inaccessible code will continue to be enshrined, codified, and amplified as the source code is re-scraped and fed back into model data training efforts.
Websites are being built via LLM-generated code and populated LLM-generated content at an exponential pace. This, in turn, raises more concerns:
- Overcoming this ever-increasing inaccessible default becomes progressively more resource-intensive. This makes it something only larger organizations can afford to take on, yet will be unwilling to due to a proportionately scaling cost.
- Inaccessible outputs become increasingly more normalized. This makes it ever more unlikely to be questioned as something that needs intervention.
Command and control
More distant—yet more relevant—fears center around explicit control. We're already seeing this manifest with refusals to communicate facts that may be inconvenient for LLM providers’ success.
More abstractly, this entire model of operation is antithetical to one of the most radical and equalizing forces humans have ever invented. And subversion of this model is deliberate.
You must imagine Sam Altman holding a knife to Tim Berners-Lee's throat.
The public internet has been available for 35 years, and open source for 28. Both are revolutionary ideas that upended traditional ways of how knowledge is distributed.
The lifespan of these ideas are also tiny blips compared to the centuries of traditional power structures and systems that came before them. It’s also enough time for said structures and systems to figure out how to address these existential threats and return things to how they prefer to operate.
Being robbed of the profound openess and transparency we have become accustomed to means that we place control of reality in the hands of closed, unaccountable organizations. Here, we need to think deeper than code.
Antifuture
There is a potential future where we are lead down a path that works against our own self-interests, amnesic to how we wound up where we are and without the language to communicate it.
Dominant players are contemptuously bypassing the standards process. We are already seeing attempts to manipulate LLM output to serve political agendas. Even further, this manipulation can occur with the providers themselves. Also recall that the more unaccountable LLM output is normalized the less we will question its outputs.
Now be the villain and imagine what is possible if these agendas feel threatened.
Before the internet there was Usenet. Before Usenet there was ARPANET. Through this lens, the browser is just another place information is stored. Here, we should be worried about the wolf-in-sheep’s-clothing threat of monopolistic vertical interoperability—interfacing what came before as a method to subsume it.
You may be reading this post as a paranoid fear response. I should point out that these fears are cultivated. Here, know that I am not feeling fear as much as anger and a desire to preserve what is boring and works.
You can open Notepad and type whatever you want into it. You can open Paint and draw whatever you can imagine. You can publish whatever you want online with a small degree of technical know-how. This all costs nothing past the hardware, software, and connection fee. We take this for granted, to our own detriment.
Being open and transparent is a radical strength, not a weakness. We should not throw this away in the pursuit of a convenient perceived inevitability.